
Introduction
OpenAI's fine-tuned models offer a powerful way to integrate advanced natural language processing capabilities into applications. This article will guide you through the process of utilizing these models in Node.js using the Axios library. We will cover the basics of fine-tuned models, setting up a Node.js environment, and provide detailed code snippets for practical implementation.
OpenAI's fine-tuned models are pre-trained on vast amounts of data and then further fine-tuned on specific tasks. This makes them powerful tools for various applications, from chatbots to content generation. In this article, we will focus on how to use these models in a Node.js environment, leveraging Axios for making HTTP requests.

Fine-tuning amplifies the capabilities of API models by delivering:
-
Enhanced Quality Outputs: Compared to conventional prompting, fine-tuning yields superior results. It refines the model's performance to provide more accurate and relevant responses.
-
Capacity to Learn from Extensive Examples: Fine-tuning surpasses the limitations of prompt length by enabling training on a larger dataset. This means the model can learn from a broader range of examples, leading to more versatile performance.
-
Token Efficiency through Concise Prompts: By using fine-tuned models, you can employ shorter prompts. This results in token savings, which is particularly valuable when working with models that have limited token capacity.
-
Reduced Latency: Fine-tuned models facilitate quicker responses, ensuring a smoother user experience with lower waiting times.
GPT models are initially trained on an extensive corpus of text. To utilize them effectively, explicit instructions and, at times, multiple examples are included in a prompt. This approach, known as "few-shot learning," demonstrates how a task should be executed.
Fine-tuning builds upon few-shot learning by incorporating a significantly larger pool of examples than what can be accommodated in a prompt. This empowers the model to excel across a wide array of tasks. Once a model has undergone fine-tuning, the necessity for including numerous examples in the prompt diminishes. This not only trims costs but also enables faster, lower-latency requests.
In broad strokes, the fine-tuning process encompasses the subsequent stages:
-
Prepare and Upload Training Data: Curate and upload the dataset that will be used to fine-tune the model's performance.
-
Train a New Fine-Tuned Model: Implement the fine-tuning process to refine the model's capabilities based on the provided dataset.
-
Deploy and Utilize Your Fine-Tuned Model: Once the fine-tuning process is complete, your model is ready to be deployed and used for various applications.
For detailed information about the cost structure associated with fine-tuned model training and usage, please refer to our pricing page.
What models can be fine-tuned?
You can currently fine-tune the following models:
-
gpt-3.5-turbo-0613 (recommended)
-
babbage-002
-
davinci-002
For most users, gpt-3.5-turbo-0613 is the recommended model due to its optimal balance between results and ease of implementation. Unless you're specifically transitioning a legacy fine-tuned model, gpt-3.5-turbo-0613 is likely the best choice.
When to use fine-tuning
Fine-tuning GPT models is a powerful enhancement, but it demands a significant investment of time and effort. It's advisable to initially explore techniques like prompt engineering, prompt chaining (dividing complex tasks into multiple prompts), and function calling. Here are the key reasons why:
-
Optimizing Prompts Can Yield Significant Improvements: Many tasks that may initially seem challenging for the models can be greatly improved with well-crafted prompts. This might negate the need for fine-tuning altogether.
-
Faster Feedback Loop with Prompt Iteration: Experimenting with prompts and similar techniques provides quicker feedback compared to the process of fine-tuning, which involves creating datasets and running training jobs.
-
Complementary Approach with Fine-tuning: In cases where fine-tuning becomes necessary, the groundwork laid in prompt engineering remains valuable. The best results are often achieved when using a well-designed prompt in the fine-tuning data, or combining prompt chaining and tool utilization with fine-tuning.
Our GPT best practices guide outlines effective strategies and tactics for achieving better performance without resorting to fine-tuning. Additionally, you can rapidly iterate on prompts using our playground for experimentation and refinement.
Common use cases
Fine-tuning proves beneficial in various common scenarios:
-
Refining Style and Quality: It's useful for setting the desired style, tone, format, and other qualitative aspects of generated content.
-
Enhancing Reliability: Fine-tuning helps ensure the model consistently produces the desired output, improving overall reliability.
-
Navigating Complex Prompts: When dealing with intricate prompts, fine-tuning can rectify instances where the model struggles to follow instructions accurately.
-
Managing Edge Cases: Fine-tuning enables the handling of specific edge cases in a customized manner, ensuring more precise responses.
-
Teaching New Skills: It's particularly valuable for training the model to perform tasks that are challenging to articulate effectively in a prompt.
A helpful perspective is to consider cases where it's more effective to "show, not tell."
Furthermore, fine-tuning can lead to cost and latency savings. By replacing GPT-4 or utilizing shorter prompts, you can achieve comparable quality with a fine-tuned get-3.5-turbo model. This can result in cost reductions and faster response times without compromising output quality. Achieving good results with GPT-4 often translates well to a fine-tuned get-3.5-turbo model by training on GPT-4 completions, potentially with a shortened instruction prompt.

Preparing your dataset
When you've determined that fine-tuning is necessary (after optimizing your prompt and identifying remaining issues), it's time to prepare the training data. You'll want to assemble a varied collection of sample conversations that mirror the kind of interactions you expect the model to handle in real-world applications.
Each example in the dataset should follow the format of our Chat completions API. This means structuring them as a list of messages, with each message containing a role, content, and optionally, a name. It's crucial to include examples that specifically address situations where the model doesn't perform as desired. Additionally, the provided assistant messages in the dataset should represent the ideal responses you aim for from the model.
Example format
In these examples, we're providing scenarios where the chatbot should deliver responses with a touch of sarcasm. This way, the training data encourages the model to understand and incorporate sarcasm appropriately in its replies.

Crafting prompts
We recommend including the set of instructions and prompts that yielded the best model performance before fine-tuning in every training example. This approach is effective, especially when dealing with a relatively small number of training examples, such as under a hundred.
If you intend to shorten or condense the repeated instructions or prompts to reduce costs, be aware that the model will likely follow these instructions as if they were explicitly provided. This can make it challenging to make the model ignore these "embedded" instructions during inference.
It's important to note that achieving desirable results may require a larger volume of training examples when fine-tuning. Since the model learns solely from demonstrations without explicit guidance, it may necessitate more data to generalize effectively.
Example count recommendations
For successful fine-tuning, a minimum of 10 examples is required. However, for optimal results, it's generally recommended to provide between 50 to 100 training examples when using the gpt-3.5-turbo model. The exact number depends on the specific use case.
Starting with 50 well-prepared demonstration conversations is a good initial approach. If the model demonstrates noticeable improvement after fine-tuning, this is a positive indicator. While this might suffice in some cases, if the model isn't yet at production quality, it suggests that providing additional data could further enhance its performance. Conversely, if there's no discernible improvement, it may be necessary to reassess how the task is set up for the model or consider restructuring the data before proceeding to a larger example set.
Train and test splits
Once you've gathered your initial dataset, it's advisable to divide it into two parts: a training set and a test set. When you submit a fine-tuning job with both training and test files, you'll receive ongoing statistics on both sets throughout the training process. These statistics serve as an initial gauge of the model's progress.
Creating a test set early on is valuable for two reasons. Firstly, it ensures you can effectively evaluate the model after training by generating samples specifically on the test set. Secondly, it provides an additional benchmark for understanding the model's performance improvements.
Token limits
Each individual training example must not exceed 4096 tokens. If an example surpasses this limit, it will be truncated to the initial 4096 tokens during training. To ensure your entire training example is fully accounted for, it's advisable to verify that the total token count in the message contents is below 4,000.
Additionally, the maximum total tokens trained per job is capped at 50 million tokens, which is determined by the total tokens in the dataset multiplied by the number of training epochs.
You can calculate token counts using our token counting notebook available in the OpenAI cookbook for reference.
Estimate costs
For precise information regarding the cost per 1,000 input and output tokens, kindly consult the pricing page. It's important to note that tokens belonging to the validation data are not included in the charges.
- To estimate the expenses for a particular fine-tuning job, employ the subsequent formula:
- Base cost per 1,000 tokens×Number of tokens in the input file×Number of epochs trained
- Base cost per 1,000 tokens×Number of tokens in the input file×Number of epochs trained
- For instance, if you have a training file comprising 100,000 tokens trained over 3 epochs, the anticipated cost would be approximately $2.40 USD.
Once you have the data validated, the file needs to be uploaded in order to be used with fine-tuning jobs:
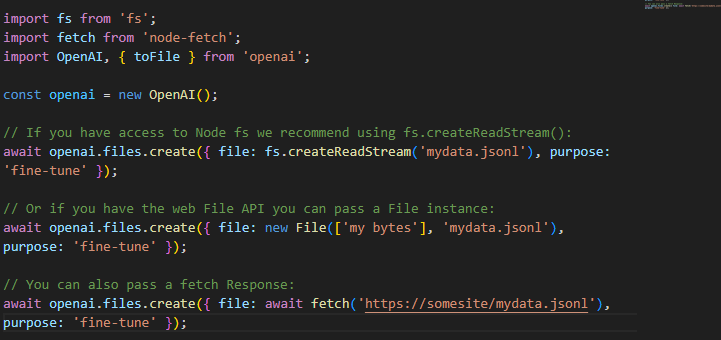
Create a fine-tuned model
After ensuring you have the right amount and structure for your dataset, and have uploaded the file, the next step is to create a fine-tuning job.
Start your fine-tuning job using the OpenAI SDK:
The base model you begin with is identified by its name, which can be either gpt-3.5-turbo, babbage-002, or davinci-002. If you wish to customize the name of your fine-tuned model, you can utilize the "suffix" parameter.
Once you initiate a fine-tuning job, it's important to note that the process may take some time to conclude. Your job might be in a queue behind other tasks in our system, and the duration of model training varies, ranging from minutes to hours, contingent on the model and the size of the dataset. Once the fine-tuning process is finished, the user who initiated the job will receive a confirmation email.
In addition to creating a fine-tuning job, you also have the capability to list existing jobs, check the status of a job, or cancel a job as needed.
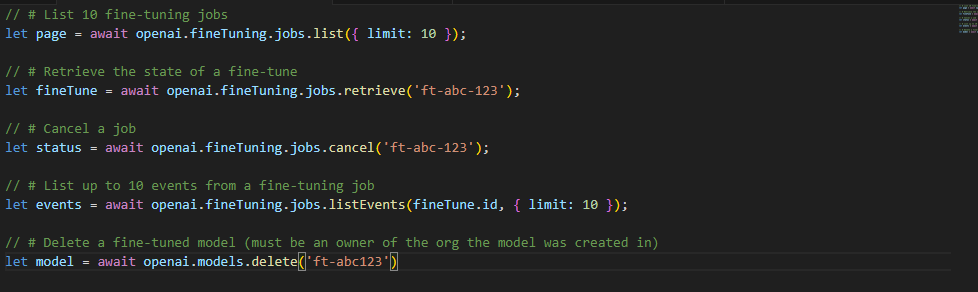
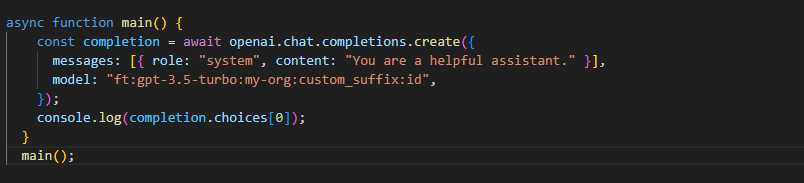
Use a fine-tuned model
Once a job has successfully completed, you will find the "fine_tuned_model" field populated with the designated model name when you retrieve the job details. You can now specify this fine-tuned model as a parameter when using the Chat completions API (for gpt-3.5-turbo) or the legacy Completions API (for babbage-002 and davinci-002). This allows you to make requests to the fine-tuned model using the Playground.
After your job concludes, the fine-tuned model should be promptly available for inference. However, in some instances, it might take a few minutes for the model to become fully operational and capable of handling requests. If you encounter timeouts or the model name can't be located, it's likely that the model is still in the process of being loaded. In such cases, it's advisable to try again in a few minutes.
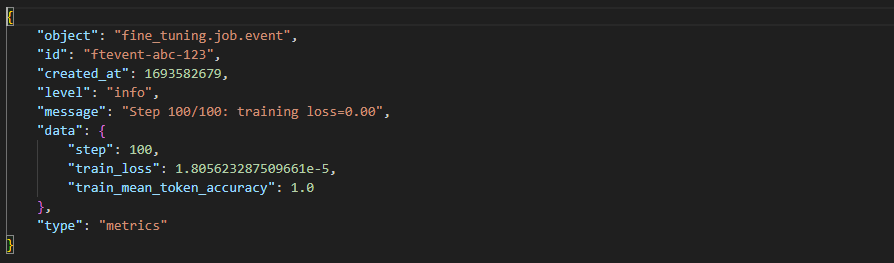
Analyzing your fine-tuned model
Throughout the training process, we furnish essential training metrics for your assessment. These metrics encompass training loss, training token accuracy, test loss, and test token accuracy. They serve as valuable indicators to ensure that the training process progresses as expected, with loss diminishing and token accuracy improving over time.
While a fine-tuning job is ongoing, you have the capability to monitor an event object that includes these pertinent metrics. This allows you to keep track of the training's progression and evaluate its performance in real-time.
While metrics can he helpful, evaluating samples from the fine-tuned model provides the most relevant sense of model quality. We recommend generating samples from both the base model and the fine-tuned model on a test set, and comparing the samples side by side. The test set should ideally include the full distribution of inputs that you might send to the model in a production use case. If manual evaluation is too time-consuming, consider using our Evals library to automate future evaluations.
Conclusion
Fine-tuning GPT models is a potent tool for tailoring them to specific applications, but it demands careful investment of time and effort. It's recommended first to optimize prompts, use prompt chaining, and employ function calling to get the best possible results. This approach is especially effective when dealing with a relatively small dataset.
If fine-tuning is deemed necessary, it's advised to include the set of instructions and prompts that worked best prior to fine-tuning in every training example. This often leads to the best and most general results, even with a modest number of training examples.
When it comes to the number of training examples, a range of 50 to 100 is typically recommended for gpt-3.5-turbo. Starting with 50 well-crafted demonstrations and assessing the model's improvement after fine-tuning is a good initial approach. If the model shows signs of progress, providing more data can lead to further improvements.
After assembling the initial dataset, it's prudent to split it into a training and test set. This allows for ongoing evaluation of the model's performance during training.
Furthermore, it's crucial to be mindful of token limits. Each training example is capped at 4096 tokens, and the total tokens trained per job should not exceed 50 million tokens.
Finally, the cost of a fine-tuning job can be estimated using the formula: base cost per 1,000 tokens * number of tokens in the input file * number of epochs trained.
In conclusion, fine-tuning is a powerful method to optimize GPT models for specific tasks. By carefully preparing data, choosing the right number of training examples, and considering costs and token limits, you can achieve impressive results.





5edc.png?width=352&name=Language%20Translation%20%281%29.png)


